在当今数据驱动的时代,海量日志的实时采集、传输与处理能力已成为衡量云服务商技术实力的关键指标之一。金山云作为领先的云服务提供商,其日志服务面临着每日高达200TB数据量的严峻挑战。为应对这一挑战,金山云选择引入Apache Pulsar作为其新一代日志服务的核心消息与流处理引擎,成功构建了高吞吐、低延迟、高可靠的日志处理管道。本文将深入剖析这一技术选型背后的考量、Apache Pulsar带来的核心优势以及具体的实践成效。
一、 挑战与选型:为何是Apache Pulsar?
金山云原有的日志处理架构在面对日均200TB、高峰时段流量激增的场景时,逐渐暴露出以下痛点:
- 扩展性瓶颈:传统消息队列在分区扩容、集群横向扩展时不够灵活平滑,难以应对业务量的指数级增长。
- 吞吐与延迟难以兼顾:需要同时满足海量数据的高吞吐写入和下游实时分析的低延迟消费需求。
- 运维复杂性高:多套系统(如用于队列、流处理、存储)堆叠导致架构复杂,运维成本和故障风险攀升。
- 数据一致性保障:在分布式环境下,确保日志数据不丢失、不重复是核心要求。
经过深度评估,Apache Pulsar以其独特的架构优势脱颖而出:
- 云原生分层架构:计算(Broker)与存储(BookKeeper)分离,使两者可以独立扩展,提供了极致的弹性。
- 统一的队列与流模型:通过“发布/订阅”模型和“流”模型的原生支持,一套系统即可同时服务实时流处理和传统队列场景,简化了技术栈。
- 高性能与低延迟:基于BookKeeper的持久化机制提供了高吞吐写入和低延迟尾部分发(Tail Read)。多层级(内存、硬盘、持久化存储)的读写设计优化了性能。
- 强大的企业级特性:内置的多租户、跨地域复制、细粒度权限控制、以及精确一次(Exactly-Once)语义支持,为大规模、多团队协作的云服务场景提供了坚实基础。
二、 Apache Pulsar在金山云日志服务中的核心实践
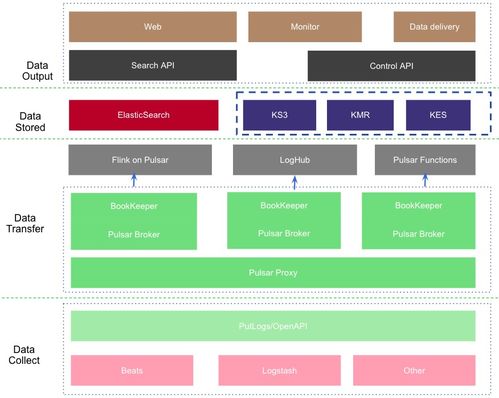
金山云基于Apache Pulsar构建了新一代日志服务数据处理管道,其核心架构流程如下:
- 日志采集与注入:遍布全球的服务器上的日志采集代理(Agent)将日志数据以高并发方式直接写入Pulsar集群。Pulsar的多租户特性为不同客户或业务线创建了逻辑隔离的命名空间(Namespace),保障了资源与数据的隔离性。
- 高可靠缓冲与传输:Pulsar集群作为核心的“数据总线”和“无限缓冲层”。其持久化存储确保所有日志消息在写入后即被安全保存,即使下游处理系统暂时故障,数据也毫发无损,实现了生产端与消费端的解耦。
- 实时流处理与消费:
- 实时监控与告警:流处理引擎(如Flink、Spark)直接订阅Pulsar主题(Topic),对日志流进行实时分析,快速检测异常并触发告警。
- 数据入仓与分析:另一路消费者将日志数据消费后写入到数据仓库(如ClickHouse、HDFS)或搜索引擎(如Elasticsearch),供离线分析和交互式查询使用。
- 灵活的多订阅模式:Pulsar支持独占、故障转移、共享和键共享(Key_Shared)多种订阅模式。金山云利用共享订阅实现消费能力的水平扩展,利用故障转移订阅保障关键处理任务的高可用。
- 弹性伸缩与运维:
- 面对流量波动,可以独立地对Broker层或BookKeeper存储层进行快速扩容,无需进行复杂的数据再平衡。
- 利用Pulsar的Topic自动过期和保留策略,结合分层存储(Tiered Storage),将冷数据从高性能存储卸载到对象存储(如S3),在保证数据可访问的显著降低了存储成本。
三、 实践成效与收益
引入Apache Pulsar后,金山云日志服务取得了显著的性能与效率提升:
- 吞吐能力飞跃:成功支撑日均200TB原始日志数据的稳定处理,峰值吞吐量大幅提升,轻松应对业务洪峰。
- 端到端延迟降低:从日志产生到可被消费或分析的端到端延迟降低至秒级,极大提升了实时监控与故障排查的效率。
- 运维简化与成本优化:
- “一栈式”架构替代了原先多组件拼装的复杂方案,降低了系统的复杂性和运维负担。
- 分层存储功能将热、温、冷数据区别存放,整体存储成本估算下降约30%-40%。
- 可靠性增强:基于Pulsar的持久化保证和跨地域复制能力,实现了日志数据的高可靠存储与容灾,服务可用性达到99.95%以上。
- 赋能业务创新:稳定的实时数据流为上层更丰富的场景(如安全情报分析、用户行为洞察、实时业务报表)提供了可能,加速了数据价值的释放。
四、 与展望
金山云的实践证明,Apache Pulsar凭借其现代化的架构设计,能够完美胜任超大规模日志数据处理场景的核心枢纽角色。它不仅解决了高吞吐、低延迟、高可用的技术挑战,更通过统一的模型简化了架构,通过云原生特性优化了成本,为日志服务乃至更广泛的实时数据管道建设提供了优秀的范式。
金山云团队计划进一步深化Pulsar的应用,例如探索Pulsar Functions实现轻量级边缘处理,利用Transformed Topic进行数据预处理,以及结合Pulsar的Schema Registry强化数据治理。这一案例也为广大面临类似海量数据处理挑战的企业提供了极具价值的参考路径:Apache Pulsar是构建下一代实时数据基础设施的强有力的候选者。